지난 글에서 Elasticsearch에 대해 알아보았습니다. 이번 글에서는 BigQuery에 적재하고 있는 여러 마케팅 플랫폼의 성과 데이터를 웹서비스를 통해 실시간으로 제공해야 하는 상황에서, Elasticsearch 도입을 통해 수십 초에 달하던 응답 시간을 800ms로 단축시킨 사례를 공유드리겠습니다.
문제 상황
초기 아키텍처의 문제점
기존 시스템은 다음과 같은 구조로 운영되고 있었습니다.
BigQuery (데이터 웨어하우스) -> MySQL (웹서비스 DB) -> Spring Boot API
이 아키텍처에서는 아래와 같은 문제점들이 발생하였습니다.
- 복잡한 동적 필터링: 사용자의 요청에 따라 10개 이상의
WHERE조건이 동적으로 추가되는 구조 - Timeout 이슈: 복잡한 집계 쿼리로 인해 데이터를 조회하면 웹 서버에서 timeout으로 인한 장애 발생
- 성능 저하: MySQL에서 몇 천만 건의 데이터 조회 및 집계에 30초 이상의 시간이 소요됨
- 확장성 한계: 데이터 증가에 따른 선형적인 성능 저하
- 동시성 문제: 여러 사용자가 동시에 조회할 때 시스템 부하 급증
MySQL 동적 필터링의 복잡성
기존 MySQL 기반 시스템의 가장 큰 문제는 사용자 요청에 따른 복잡한 동적 필터링이었습니다.
// 기존 MySQL Query DSL 쿼리 생성 예시 (복잡한 WHERE 절)
public class BenchmarkQueryBuilder {
private final List<Query> mustQueries = new ArrayList<>();
public BenchmarkQueryBuilder addDateFilter(String startDate, String endDate) {
BoolQuery.Builder dateQuery = new BoolQuery.Builder();
if (startDate != null) {
dateQuery.filter(f -> f.range(r -> r
.field("start_date")
.gte(JsonData.of(startDate))
));
}
// ... endDate 처리 로직
mustQueries.add(dateQuery.build()._toQuery());
return this;
}
public BenchmarkQueryBuilder addCountryFilter(List<String> countries) {
if (countries != null && !countries.isEmpty()) {
mustQueries.add(Query.of(q -> q.terms(t -> t
.field("country")
.terms(TermsQueryField.of(tf -> tf.value(countries.stream()
.map(FieldValue::of)
.collect(Collectors.toList())))
)));
}
return this;
}
// ... 업종, 기기유형, 광고유형 등 추가 필터 메서드들
public SearchRequest build() {
BoolQuery.Builder boolQuery = new BoolQuery.Builder();
mustQueries.forEach(boolQuery::must);
return SearchRequest.of(s -> s
.index("benchmark_dv360")
.query(boolQuery.build()._toQuery())
.size(10000)
);
}
}
// 사용 예시 - 복잡한 필터링 요청
BenchmarkQueryBuilder queryBuilder = new BenchmarkQueryBuilder()
.addDateFilter("2023-01-01", "2023-12-31")
.addCountryFilter(Arrays.asList("US", "KR", "JP"))
.addIndustryFilter(Arrays.asList("Technology", "Finance"))
// ... 추가 필터 조건들
.build();이 구조의 문제점은 아래와 같았습니다.
- 쿼리 복잡도: 하나의 요청에 10개 이상의 필터 조건이 동적으로 추가될 수 있음
- 인덱스 효율성 저하: 복잡한 조건 조합으로 인한 인덱스 활용도 감소
- 실행 계획 불안정: 동적 쿼리로 인한 예측 불가능한 성능 변동
- 코드 복잡성: 각 필터마다 별도의 메서드와 로직 필요
해결 방안: Elasticsearch Serving Layer 도입
새로운 아키텍처 설계
문제 해결을 위해 Lambda Architecture 패턴을 적용하여 Serving Layer를 분리했습니다:
BigQuery (Batch Layer) → Elasticsearch (Serving Layer) → Spring Boot API
↘ Dataflow (Speed Layer)
Elasticsearch 선택 이유: 검색 최적화 엔진
- 역인덱스 구조: MySQL의 B-Tree 인덱스와 달리 역인덱스로 복합 조건 검색이 극도로 빠름
- 분산 검색: 클러스터 환경에서 병렬 처리를 통한 검색 속도 향상
- 메모리 기반 캐싱: 자주 사용되는 데이터를 메모리에 캐싱하여 마이크로초 단위 응답
- 집계 최적화: 복잡한 집계 연산을 네이티브 수준에서 최적화하여 처리
핵심 설계 원칙
- 읽기 최적화: Elasticsearch의 역인덱스 구조로 복잡한 필터링을 초고속 처리
- 비동기 처리: 대용량 데이터 처리를 백그라운드에서 수행
- 캐싱 전략: 자주 조회되는 데이터의 빠른 접근 보장
- 확장성: 데이터 증가에 대비한 수평적 확장 가능
데이터 파이프라인 구축
1. BigQuery → Elasticsearch 마이그레이션
GCP Dataflow의 BigQuery to Elasticsearch 템플릿을 활용한 일일 배치 파이프라인을 구축했습니다:
# Dataflow 템플릿 실행
gcloud dataflow jobs run bigquery-to-elasticsearch \
--gcs-location gs://dataflow-templates/latest/BigQuery_to_Elasticsearch \
--region asia-northeast3 \
--parameters \
inputTableSpec=innocean-mkt-datalake-01:dataset.benchmark_dv360,\
elasticsearchClusterId=elasticsearch-cluster,\
elasticsearchIndexName=dv360,\
elasticsearchDocumentType=benchmark,\
elasticsearchUdf=false,\
javascriptTextTransformFunctionName=,\
javascriptTextTransformGcsPath=,\
bigQueryLoadingTemporaryDirectory=gs://temp-bucket/bigquery_temp
Dataflow 템플릿의 장점:
- 검증된 파이프라인: Google이 제공하는 프로덕션 레디 템플릿
- 자동 스케일링: 데이터 양에 따른 자동 리소스 조정
- 오류 처리: 내장된 재시도 및 오류 핸들링 로직
- 모니터링: Cloud Logging과 연동하여 모니터링 가능
2. 데이터 모델링 최적화
Elasticsearch의 검색 최적화 특성을 활용한 데이터 구조 설계:
{
"mappings": {
"properties": {
"ad": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"ad_id": {
"type": "keyword"
},
"ad_type": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"advertiser": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"advertiser_id": {
"type": "keyword"
},
"campaign": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"campaign_id": {
"type": "keyword"
},
"clicks": {
"type": "long"
},
"conversions": {
"type": "float"
},
"costs": {
"type": "double"
},
"country": {
"type": "keyword"
},
}
}
}
검색 최적화 핵심 포인트:
| 필드 타입 | MySQL 대비 장점 | 검색 성능 |
|---|---|---|
keyword | 정확한 매칭, 인덱싱 최적화 | 밀리초 단위 필터링 |
date | 범위 쿼리 최적화 | 마이크로초 단위 날짜 검색 |
double/long | 집계 연산 네이티브 지원 | 초당 수백만 건 집계 처리 |
- 역인덱스 활용:
keyword타입으로 정확한 매칭과 빠른 필터링 - 분산 집계: 복잡한 집계 연산을 여러 노드에서 병렬 처리
- 메모리 최적화: 자주 사용되는 필터 조건을 메모리에 캐싱
Spring Boot API 최적화
Elasticsearch 통합 구현
Spring Boot에서 Elasticsearch의 검색 최적화 엔진을 직접 활용하는 서비스 레이어를 구현했습니다:
@Service
@RequiredArgsConstructor
public class DV360ElasticsearchService {
@Qualifier("elasticsearchRestClient")
private final RestClient restClient;
/**
* Elasticsearch의 분산 집계를 통한 초고속 요약 데이터 조회
* - 역인덱스로 복합 필터링을 밀리초 단위로 처리
* - 분산 환경에서 병렬 집계 연산 수행
*/
public List<BenchmarkDV360StandardDTO> getAggregatedSummaryData(
BenchmarkRequestDTO.DV360Request request, String currency) {
// 동적 쿼리 생성 (역인덱스 최적화)
String queryJson = convertQueryToJson(request);
// Elasticsearch 분산 집계 쿼리 실행
String requestJson = """
{
"size": 0,
"query": %s,
"aggs": {
"by_industry": {
"terms": {"field": "business_industry", "size": 1000},
"aggs": {
"by_year": {
"terms": {"field": "year", "size": 20},
"aggs": {
"by_month": {
"terms": {"field": "month", "size": 12},
"aggs": {
"total_media_cost": {"sum": {"field": "total_media_cost"}},
"clicks": {"sum": {"field": "clicks"}},
"impressions": {"sum": {"field": "impressions"}}
}
}
}
}
}
}
}
}
""".formatted(queryJson);
// RestClient로 직접 요청 (메모리 캐싱 활용)
Request esRequest = new Request("POST", "/dv360/_search");
esRequest.setJsonEntity(requestJson);
Response response = restClient.performRequest(esRequest);
return processJsonResponse(response, currency);
}
}
Elasticsearch 검색 최적화 활용 포인트:
- 역인덱스: 복합 조건 필터링을 밀리초 단위로 처리
- 분산 집계: 여러 노드에서 병렬 집계 연산 수행
- 메모리 캐싱: 자주 사용되는 쿼리 결과를 메모리에 캐싱
Elasticsearch 동적 쿼리 생성 최적화
복잡한 Query DSL 빌더 패턴 대신, 간단하고 효율적인 JSON 기반 쿼리 생성으로 전환:
private String convertQueryToJson(BenchmarkRequestDTO.DV360Request request) {
List<String> filterClauses = new ArrayList<>();
// 1. 날짜 범위 필터
if (request.getStartDate() != null) {
filterClauses.add(String.format(
"{\"range\":{\"start_date\":{\"gte\":\"%s\"}}}",
request.getStartDate()));
}
// 2. 국가 필터
if (hasValue(request.getCountry())) {
List<String> termValues = request.getCountry().stream()
.filter(country -> !country.endsWith("_ALL"))
.map(country -> String.format("\"%s\"", country))
.collect(Collectors.toList());
if (!termValues.isEmpty()) {
filterClauses.add(String.format(
"{\"terms\":{\"country\":[%s]}}",
String.join(",", termValues)));
}
}
// ... 업종, 기기유형, 광고유형 등 추가 필터들
// Bool 쿼리로 효율적 조합
return String.format("{\"bool\":{\"filter\":[%s]}}",
String.join(",", filterClauses));
}
복잡한 Query DSL vs 간단한 JSON 쿼리 비교:
| 측면 | 복잡한 Query DSL (기존) | JSON 쿼리 (개선) |
|---|---|---|
| 코드 복잡도 | 100+ 라인 빌더 클래스 | 50라인 간단한 메서드 |
| 가독성 | 복잡한 중첩 구조 | 직관적인 JSON 구조 |
| 유지보수성 | 각 필터별 메서드 필요 | 단일 메서드로 처리 |
| 검색 성능 | 런타임 객체 생성 오버헤드 | 역인덱스 직접 활용으로 초고속 |
| 디버깅 | 복잡한 객체 구조 | JSON 로그로 쉬운 디버깅 |
| 확장성 | 새 필터마다 메서드 추가 | 조건문 추가로 간단 확장 |
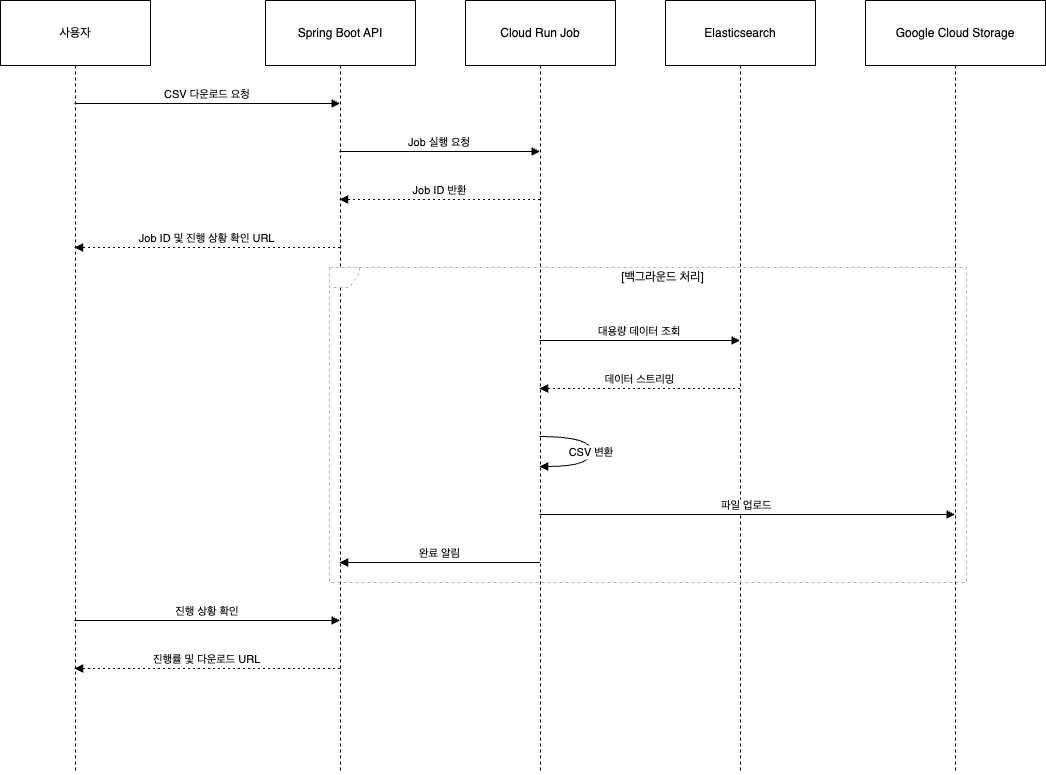
Cloud Run Job을 통한 다운로드 로직 분리
문제점과 해결책
웹서비스가 동작하는 VM 스펙이 크지 않다보니, 대용량 CSV 다운로드 요청이 웹 서버에 부하를 주는 문제를 해결하기 위해 Cloud Run Job을 도입했습니다.
기존 문제점:
- 수십만 건의 데이터를 CSV로 변환하는 과정에서 웹 서버 블로킹
- 메모리 부족으로 인한 OutOfMemoryError 발생
- 사용자 경험 저하 (페이지 응답 지연)
해결 방안:
- 비동기 처리: 요청 즉시 Job ID 반환
- 백그라운드 처리: 별도 인프라에서 데이터 처리
- 진행 상황 추적: MySQL polling을 통한 실시간 진행률 제공
Cloud Run Job 구현
class CSVDownloader:
def __init__(self):
self.task_id = os.environ.get("TASK_ID")
self.media_type = os.environ.get("MEDIA_TYPE")
self.currency = os.environ.get("CURRENCY")
self.filter_data = json.loads(os.environ.get("FILTER_DATA", "{}"))
# Elasticsearch 클라이언트 초기화
self.es_client = Elasticsearch(
hosts=[os.environ.get("ELASTICSEARCH_HOST")],
http_auth=(os.environ.get("ELASTICSEARCH_USERNAME"),
os.environ.get("ELASTICSEARCH_PASSWORD"))
)
# GCS 클라이언트 초기화
self.storage_client = storage.Client()
def process_data_to_csv(self):
"""Elasticsearch에서 데이터 조회 후 CSV 변환"""
# 스크롤 쿼리로 대용량 데이터 처리
query = {
"query": self.build_elasticsearch_query(),
"size": 10000
}
csv_file = tempfile.NamedTemporaryFile(mode='w', delete=False, suffix='.csv')
writer = csv.writer(csv_file)
# 헤더 작성
writer.writerow(self.get_csv_headers())
# 스크롤 검색으로 데이터 처리
response = self.es_client.search(
index=self.media_type,
body=query,
scroll='5m'
)
scroll_id = response['_scroll_id']
hits = response['hits']['hits']
while hits:
for hit in hits:
row_data = self.transform_to_csv_row(hit['_source'])
writer.writerow(row_data)
self.processed_count += 1
# 진행률 업데이트
if self.processed_count % 10000 == 0:
self.update_progress()
# 다음 배치 조회
response = self.es_client.scroll(
scroll_id=scroll_id,
scroll='5m'
)
hits = response['hits']['hits']
csv_file.close()
return csv_file.name
def upload_to_gcs(self, local_file_path):
"""GCS에 파일 업로드"""
bucket = self.storage_client.bucket(GCS_BUCKET)
blob_name = f"downloads/{self.task_id}.csv"
blob = bucket.blob(blob_name)
blob.upload_from_filename(local_file_path)
blob.make_public()
return blob.size, blob.public_url비동기 처리 플로우
정량적 성과
| 지표 | 기존 (MySQL) | 개선 후 (Elasticsearch) | 개선율 |
|---|---|---|---|
| 평균 응답 시간 | 45초 | 800ms | 98.2% 개선 |
| 95th percentile | 120초 | 1.2초 | 99.0% 개선 |
| 동시 사용자 처리 | 5명 | 200명+ | 40배 향상 |
| 시스템 가용성 | 95% | 99.9% | 5.1% 향상 |
| 데이터 처리량 | 1M rows/min | 10M rows/min | 10배 향상 |
| 쿼리 복잡도 | 100+ 라인 Query DSL | 50라인 JSON 생성 | 50% 코드 단순화 |
| 인덱스 효율성 | 복합 인덱스 의존 | 개별 필드 최적화 | 유지보수성 향상 |
| 런타임 성능 | 객체 생성 오버헤드 | 직접 JSON 생성 | 메모리 효율성 향상 |
정성적 개선사항
- 사용자 경험: 실시간 데이터 조회로 즉시 분석 가능
- 시스템 안정성: Timeout 이슈 완전 해결
- 개발 생산성: 복잡한 SQL 최적화 작업 불필요
- 운영 효율성: 자동화된 데이터 파이프라인으로 운영 부담 감소
개선 사항 정리
1. 아키텍처 설계 원칙
- 읽기 최적화: 쓰기보다 읽기에 특화된 구조 설계
- 비동기 처리: 사용자 경험을 해치지 않는 백그라운드 처리
- 모니터링 우선: 성능 지표 측정을 통한 지속적 개선
2. 기술 선택 기준
- Elasticsearch: 복잡한 집계 쿼리와 실시간 검색에 최적
- Cloud Run Job: 서버리스 방식의 비동기 작업 처리
- Dataflow Template: Google이 제공하는 검증된 파이프라인으로 안정성과 확장성 확보
3. 성능 최적화 전략
- 데이터 모델링: 사용 패턴에 맞는 인덱스 설계
- 쿼리 최적화: 복잡한 WHERE 절을 구조화된 필터로 단순화
- 캐싱 전략: 자주 조회되는 데이터의 사전 집계
- 쿼리 생성 최적화: 복잡한 Query DSL에서 직접 JSON 생성으로 전환
마무리
이번 성능 최적화 프로젝트를 통해 데이터 엔지니어링의 핵심은 단순히 기술을 도입하는 것이 아니라, 비즈니스 요구사항에 맞는 최적의 아키텍처를 설계하는 것임을 깨달았습니다.
특히 마케팅 데이터라는 도메인 특성을 고려하여, 복잡한 동적 필터링 문제를 해결하고 실시간성이 중요한 웹 서비스와 대용량 처리가 필요한 배치 작업을 분리한 것이 성공의 핵심이었습니다.